
Making the Case for Synesis One (SNS), the Decentralized Scale AI
Decentralized compute has been all the rage, but what about decentralized and gamified data labeling?

Key Highlights:
We all know how high-end chips essential to run LLMs are relatively scarce and in high demand. Further compounding the problem are talks about whether we even have proper infrastructure to power AI at scale (i.e. enough data centers, or sufficient energy / electricity).
Equally important, though often overlooked (especially in the crypto space), is the data used for training LLMs. There are a few key points:
There is an enormous amount of data in the world, but much of this is of suspect quality. For instance, ChatGPT-4 was trained on approximately 1 petabyte of data. The Library of Congress holds over 20 petabytes, and companies like JP Morgan have more than 100 petabytes within their walled gardens. But in this case, data quantity != data quality. Much of the world's data can be thought of as just a vast amount of stuff.
There are worries that we’re going to run out of high quality language data within the next few years.
Given the vast amounts of data available, distinguishing good data from bad data is crucial. High-quality datasets are vital.
Synthetic data, while promising, isn't quite there yet. To fully unlock its potential, continuous human refinement and curation will likely be needed.
Don’t believe me? Consider this insight from someone at OpenAI:
“What this manifests as is – trained on the same dataset for long enough, pretty much every model with enough weights and training time converges to the same point. Sufficiently large diffusion conv-unets produce the same images as ViT generators. AR sampling produces the same images as diffusion. This is a surprising observation! It implies that model behavior is not determined by architecture, hyperparameters, or optimizer choices. It’s determined by your dataset, nothing else. Everything else is a means to an end in efficiently delivering compute to approximate that dataset.” (emphasis mine)
As models get smarter, we’ll likely need more specialized and high-quality data. Think of specialized use cases around healthcare, autonomous driving, law, and more. Additionally, good data sets will also unlock efficiencies during the training process (i.e. a model trained on high quality data will lead to more capable models).
When looking at the investment landscape currently, there are limited ways to play data growth in public markets, and the overall need for specialized data. This is especially true in the crypto space (Grass is one of the few projects that comes to mind but has yet to launch its token). On the other hand, compute projects are becoming relatively commoditized, and it already feels like we’re reaching saturation between launched and unlaunched projects.
Taking a quick glance at the decentralized compute / training sector, there are projects like Io.net, Akash, Render, Nosana, Prime Intellect, Allora Network, TAO, among many others. While these projects vary in focus and aren’t perfect comps with each other, they collectively highlight the breadth of projects working on decentralized compute / training.
On the other hand, there aren’t many pure-play data companies, and a massive valuation gap exists between Synesis One (~$34 million FDV) and web2 comparables like Scale AI ($14 billion valuation), LabelBox (~$1 billion valuation), among others. In the crypto space, Grass has yet to launch, but its launch could serve as another catch-up play catalyst, depending on its initial valuation. Decentralized GPU / DePin plays trade in the multibillion dollar valuation range despite a handful of these projects with limited differentiation and uncertain demand.
The Data Problem & Why Its Important
Most readers are likely familiar with LLMs (Large Language Models) like ChatGPT and Gemini, and understand the substantial compute and specialized chips they require — just look at NVDA stock over the past three years for a refresher.
This is partly why there’s a plethora of decentralized compute projects aiming to solve this problem (e.g., Io.net, Akash Network, Render), along with various Web2 companies (e.g., CoreWeave). These companies are making it easy for anyone, anywhere, to access high-quality chips. It becomes clear quite fast that we need compute, and lots of it.
However, compute (i.e. chips) is only part of the LLM equation. At a basic level, LLMs need two things: i) Computing power (i.e. the architecture, chips, training), and ii) Data sets to train these LLMs.
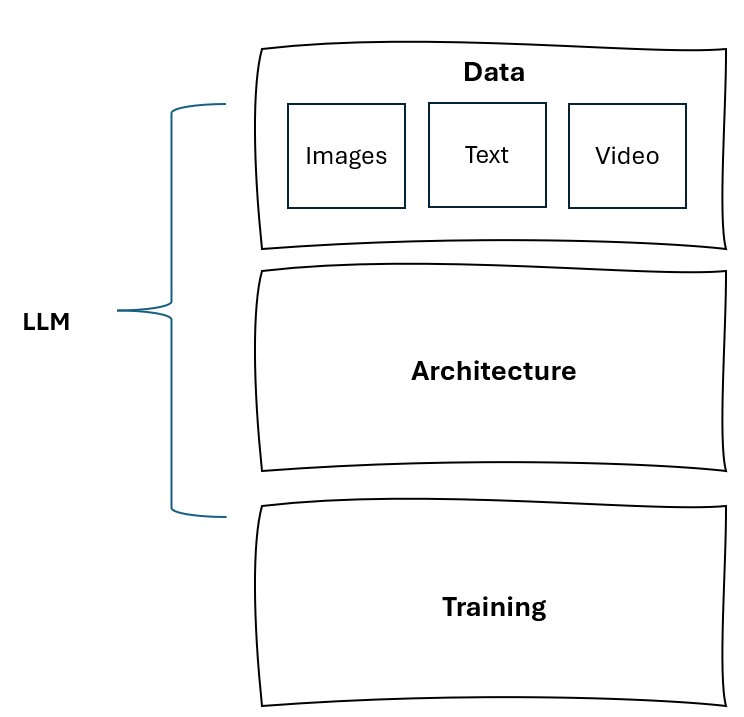
Early iterations of LLMs were built using vast quantities of data from a variety of sources: scientific papers, Wikipedia pages, news articles, etc. As they improved, they continued training on more and more datasets. However, anyone who’s worked with data knows it’s garbage in, garbage out. On the internet? There’s a lot of garbage.

This is where data labeling and annotation come in. Having vast quantities of data is one thing, but high-quality data? That can be a game-changer.
Companies like SNS and Scale AI are positioned to help with data annotation and labeling (this is also referred to as RLHF or Reinforcement Learning from Human Feedback). This can mean correctly labeling data in expected ways, such as differentiating a car from a bus or identifying a traffic light. Another simple example is one of the captchas below that we’ve all completed. There are a few examples that are clearly buses, some are cars, and some boxes have neither. But the model doesn’t know that until the data is correctly labeled and sorted.

Now imagine this process repeated hundreds or thousands of times. This can be done for anything: filtering images, identifying objects in videos, fixing grammatical errors, correcting typos, etc. The refinement process eventually looks like this:
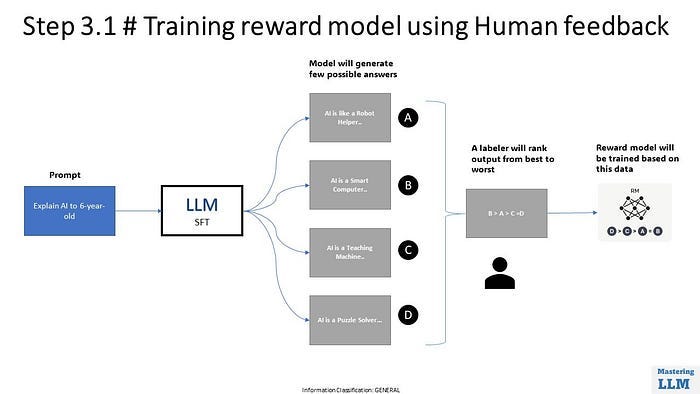
The Synesis One Solution:
Synesis One is a decentralized platform that utilizes tokenized incentives and play-to-earn mechanics to help label and annotate datasets that are used to train AI Models. Like its Web2 competitors, the company employs a remote workforce, compensating individuals for their contributions.
There are already thousands of people in emerging and third world countries working on data labeling, largely in the Philippines (this will be unsurprising to anyone who’s followed Axie Infinity and other play-to-earn games). For example, Scale AI employs thousands of workers in the Philippines through a subsidiary, Remotasks, where people can work remotely and earn by completing tasks. Synesis One improves on the existing ecosystem by offering immediate payment through the SNS token in a world rife with complaints about payments being withheld or not being distributed.1
At a high level, there are three parts to the Synesis One ecosystem:
Supply / Workers: These workers train and label data, earning rewards in the form of the SNS token. Think of it as “train-to-earn” instead of play-to-earn.
Clients: End consumers who need data labeled and cleaned. They can launch campaigns with Synesis One to have workers complete specific tasks tailored to their needs. Weekly and monthly data campaigns allow people to participate, with submissions directly powering AI solutions for clients.
NFT Holders (Kanon NFTs): There are 10k Kanon NFTs, each correlating with different words. Before labeling and annotating data, workers must either hold an NFT themselves to earn or be part of a guild (similar to other play-to-earn platforms) that holds an NFT. Kanon NFT owners receive passive income in the form of SNS tokens based on how frequently their word is used by end clients.
Additionally, Synesis provides various ad-hoc AI solutions through its sister company, MindAI, for enterprises. Mind AI utilizes symbolic AI (i.e. logic based AI that was prominent pre machine learning models, etc.), this allows Synesis to perform inferences that are fully traceable and transparent. The co. will offer to integrate their model with LLMs to provide near-hallucination free implementations.
SNS Token & Value Accrual
Initially, companies / clients that initiate a campaign must pay in SNS token, which is deposited into a smart contract that gets allocated to workers and validators as work is completed. After the campaign ends, workers and validators claim their rewards from the smart contract vault.
Burn Mechanism (Not yet implemented):
After campaigns end, a low single-digit percentage of rewards typically go unclaimed. These unclaimed rewards will be burned, in addition to platform fees.
Token Sinks (Coming soon):
SNS staking requirements for workers and validators. Workers will have to stake a portion of SNS before participating in a campaign. This will incentivize high-quality work, as low-quality work or malicious behavior will lead to staked tokens being slashed.
The creation of a Guild (used to pool resources and lower worker barriers) will require some payment of the SNS token.
Market Comps & Valuation
Synesis One raised $9.5mm in its inaugural and only token presale in 2021 with participating investors including Cultur3 Capital, MetaCartel VC, Kenetic Capital, Shima Capital, among others. While its hard to say for sure, I have a feeling if the company raised in private markets today as a decentralized data labeling project, it’d have no trouble raising, and raising a lot (again, just look at what some decentralized compute projects have raised).
Competition in the data labeling market is significant, with a few large-scale private companies:
Scale AI: Raised $1bn in May 2024, achieving a $13.8bn valuation. This is nearly double the $7.3bn valuation reached after a $325 million raise in April 2021.
LabelBox: Raised $110mm in January 2022 at an undisclosed valuation, but the founders hinted at a valuation of around $1bn.
Sama: Raised $70mm in a Series B round in November 2021.
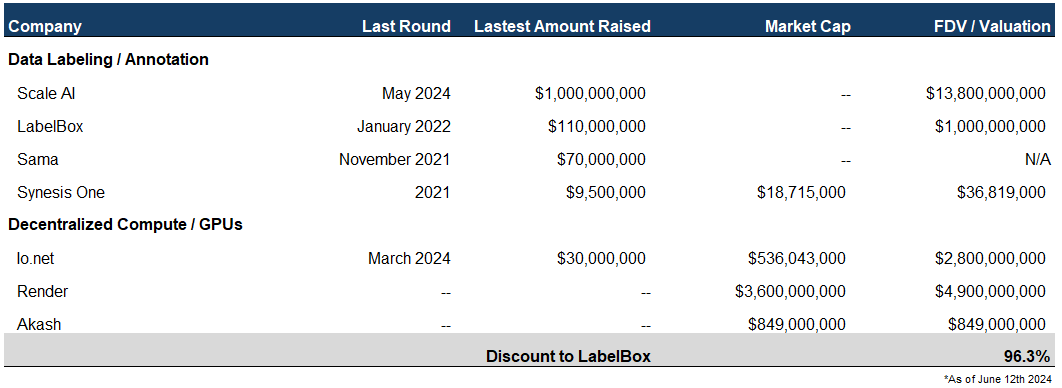
Given that Synesis One (SNS) trades at roughly $19mm Market Cap / $37mm FDV, there’s a significant discount compared to the latest valuations of Scale AI and LabelBox. There’s also a notable disconnect in the valuations between SNS and decentralized GPU providers like Io.net, Render and Akash which all trade at multi-hundred million to billion dollar valuations given the narrative around AI / DePin.
While I won’t delve into the valuations of prior crypto play-to-earn models, it’s worth noting that Axie Infinity peaked at $30bn Market Cap due to its play-to-earn mechanics and flywheel. Even reaching half of LabelBox’s last valuation would result in a 10x+ increase from current prices. I don’t expect SNS to reach Axie Infinity or Scale AI levels, but that’s the point — it doesn’t need to in order to be a great trade.
This article talks at depth about the underworld of AI data labeling, painting some of the existing web2 co’s in a harsh light: https://www.washingtonpost.com/world/2023/08/28/scale-ai-remotasks-philippines-artificial-intelligence/